2024:On-Device AI 發展到哪?

Google launches Gemini, its biggest challenge to OpenAI
2024,AI Boom 的第二年,我們總算可以撥開 AI 迷霧,逐一聊聊大型語言模型 (LLM) 的實際應用。
畢竟模型大了幾 B,Benchmark 喊的好聽,如果最後沒辦法成功部署、商業化,那真的是一毛錢都賺不到 XD
那首先,我們就來聊聊 On-Device AI 的發展現況。
---
23 年我們講「LLM in your pocket」時,提了一堆的困難,感覺 LLM in your pocket 還是個夢。
比如說 Memory Wall,終端設備記憶體太小了,如果硬把當時算強、算小的 Model LLaMA-7B 放到手機上,直接就吃掉 14 GB 的記憶體空間。
給個參考點,當代最強 iPhone 15 Pro 也只有 8 GB 的 DRAM。
那既然放 RAM 不可行,能不放到慢一點的儲存晶圓呢?可以,但隨之而來就是「慢」。
就像尖峰時段,用 Copilot GPT-4 一樣,等一個字要等個一兩秒,考驗 User 的耐心和易怒程度。
於是在一切很不明朗,On-Device AI 大家都沒頭緒的狀況下,23 年底我們看到了一點曙光。
Gemini Nano - 谷歌的起手式
首先 Google 在 12 月初,把 Gemini 系列中最小的 Nano,放到 Pixel 8 Pro 了。Pixel 8 Pro 也順勢成為第一個裝上 Gemini Nano 的 Android 手機。
AI-powered phone,裝上 Nano 後,他就多了「智慧選字 (Smart Reply)」、「智慧穩定(Video Boost)」、「去模糊(Unblur)」等功能,直接炫砲起來。
大家可能想,前面才提到模型大到放不下,怎麼一個突然就塞進去了手機?
秘訣就是「Quantization」與「Pruning」。
Quantization 指,用低一點的精準度計算,容許一點誤差。
舉個例子,1.30111199998 = 2.60219。如果算不精準一點,1.301.99 = 2.58。
明顯 2.6 & 2.58 看起來差不多,但你在計算過程中,卻省掉一堆位數,節省一堆空間!這大致就是 Quantization 的簡單例子。
實務上,我們可能用 Linear Mapping 等方法,把訓練好的模型,轉換成低精準度的數字,做成推論(Inference)模型。
另一方面,則是「Pruning」,把那些不重要的參數,拿掉!
現今大部分的語言模型,都有一個很大 Deep Neural Network (深度神經網路)。
像你大腦一樣的神經網路,其實很多 Neuron 節點是不太重要的,拿掉雖會犧牲一點品質,但也能有效降低模型大小。
回到 Gemini Nano,不像多數 Model 都用 16-bit (FP16) 的精準度,Gemini Nano 只有 4-bit 的精準度。
同時,大概只有 1.8 B 或 3.25 B 大。由於精準度較低,大概只會佔裝置 1.7 GB 的大小,放在手機上就變得容易不少!
Apple 想另一邊 - 客制 Data Flow
在 AI 競賽慢慢跑,還在醞釀 Vision Pro 混合實境的 Apple ,在 12 月中發佈了論文 《 LLM in a flash: Efficient Large Language Model Inference with Limited Memory 》,成為 AI 第一響。
簡單的說,它探討的是:既然 DRAM 不夠用,能不能借用慢一點的 Flash Memory,但又不損失性能。
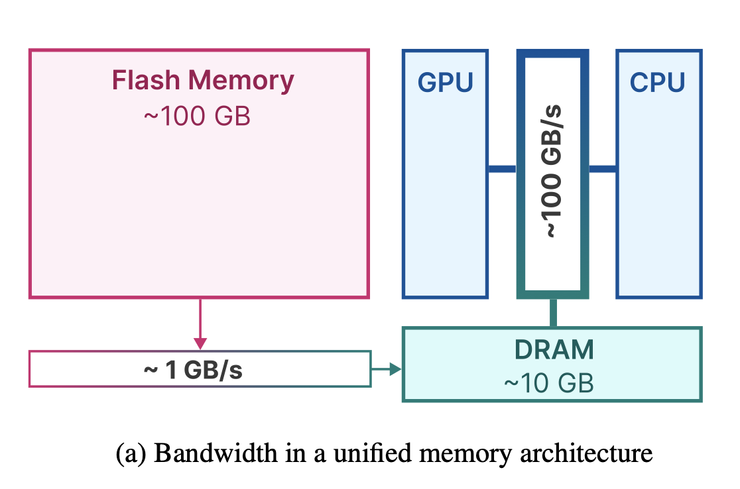
在過去, Flash Memory 通常是隨身碟、記憶卡的儲存晶圓,有 Random Access(隨機存取)快,比 DRAM 單元價格低、容量更大的特性。
同時,如果增加一次讀取的量 (a chunk of size),Flash Memory 就會有更好的 Throughput。
並且,Apple 團隊發現,在 LLM 模型架構中 (Feed-Forward Network, FNN layer) ,有 90% 之高的稀疏性 (Sparsity)。
借助上述特型,Apple 提出一個框架:
- 只從 Flash Memory ,搬重要的參數到 DRAM,供計算單元計算 (CPU、GPU)。
- 把上下左右、附近的參數合在一起讀,提高 chunk size 。
- 用 Sliding Window 的方法,只存最近的 token 在 DRAM ,把最遠的 token 從 DRAM 丟掉。
透過這些技巧,我們可以讓裝置跑比 DRAM 兩倍大的模型,CPU 推論上提高 4 到 5 倍,GPU 則提高 20 到 25 倍。
這篇論文揭露了,就算 Model 不 Quantization、Prune ,我還是可以整個塞進去手機和筆電。
那 On-Device AI 有多重要?
很重要,尤其在算力等於石油的時代,更重要。
從近期 Nvidia 市值超過 Google 巨頭為例,算力的市場價值,已經飆到不可理喻的狀態。但算力代表花錢,越多使用者就花越多錢。
既然 AI 進產品是趨勢,讓 Device 分擔計算能力,分散掉伺服器的計算壓力,正是這些 有賣行動裝置的公司,如 Apple、Google,正努力的方向。
事實上, Federated Learning 已經是 System 領域研究已久的主題,近期學界也逐步聚焦在 LLM、 Transformer-based 的特徵上進行研究。
可預見的未來,我們每個裝置,都有一個 AI 腦。
結語
老實說,我個人蠻期待 Apple 的發展。
幾週前 9to5Mac 揭露 Apple 正增強 Siri 和 Message 的 AI 技能,借助 OpenAI ChatGPT 的 API ,去強化自家 Model 的品質。
看起來 Apple 正在努力、iOS 18 將成為第一個 AI-Powered OS,也希望以後 Siri 真的很強,可以都交給他做任何事了~
