前綴和應用: 總和=k的子陣列有幾個 Subarray Sum Equals K_Leetcode #560

題目敘述
題目會給我們一個輸入陣列nums,和一個指定的k值。
請問,在輸入陣列nums中,有幾個子陣列的元素總合恰好為k ?
例如: nums = [1,2,3], k = 3
則有兩個子陣列的元素總合為3,分別是[1,2] 和 [3]
如果是第一次聽到或接觸前綴和prefix的同學,請先參考這篇解題教學文章,因為接下來,我們會用到前綴和的觀念去解題。
測試範例
Example 1:
Input: nums = [1,1,1], k = 2
Output: 2
有兩個子陣列的元素總合為 k = 2
[1,1] 和 [1,1]
前兩個1 和 後兩個1
Example 2:
Input: nums = [1,2,3], k = 3
Output: 2
有兩個子陣列的元素總合為 k = 3
[1,2] 和 [3]
約束條件
Constraints:
1 <= nums.length <= 2 * 10^4
輸入陣列nums的長度介於1~兩萬之間。
-1000 <= nums[i] <= 1000
每個陣列元素值界於 -1000 ~ 1000
-10^7 <= k <= 10^7
指定的k值介於 負一千萬~正一千萬 之間。
演算法 從第一直覺的想法,演化到進階的前綴和高速計算區間和(以前正好學過)
第一直覺的想法可能是直接用兩層迴圈去找,第一層找所有可能的左端點left,第二層找所以可能的右端點right,再計算[left, right]區間內的元素總合是否剛好=k,去累積子陣列個數。
這個想法算是暴力展開法,面對題目的陣列輸入長度高達 兩萬 個完素,暴力搜索將付出平方等級的代價,高達 10*8 等級的搜索成本,明顯會有太慢time-out超過平台限制的風險。
這邊,我們會借用前面學過透過prefix sum 來高速計算 range sum的技巧,來降低演算法的複雜度,題生程式執行效率。
一開始,先建立一個字典,鍵值是prefix sum,value則是這個prefix sum的出現次數。
接著,建造一個迴圈,從左到右,逐漸更新前綴和 prefix sum,接著檢查
prefix sum - k 這個比較小的值以前有沒有出現過?
假如有,代表已經找到子陣列=k的區間,累加子陣列=k的的出現次數。
接著更新當下的prefix sum的出現次數,寫到字典裡面。
依照同樣的模式,反覆迭代。
最後,子陣列=k的的出現次數計數器的值,就是題目所求,也是最終回傳的答案。
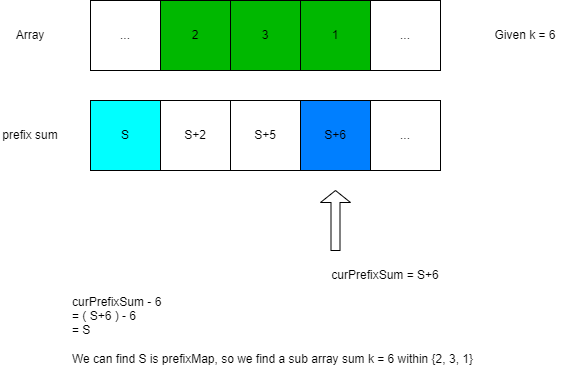
以下圖說明演算法精神,假設今天題目給的k值=6
當下我正好計算到箭頭指向的地方,目前累積的prefix sum前綴和 = S + 6
那我們就去檢查 (S + 6 - k) = S + 6 - 6 = S 這個值以前有沒有出現過?
如果有,S以前出現在淺藍色的那個格子,代表從上一次出現的地方到目前這個位置,剛好構成一組子陣列,區間內的元素總合 = k = 3 + 2 + 1 = 6
image
程式碼 用 前綴和 高速計算 區間和(以前正好學過)
class Solution:
def subarraySum(self, nums: List[int], k: int) -> int:
# prefix sum
cur_prefix_sum = 0
# counter of subarray with sum = k
counter = 0
# key: subarray prefix sum
# value: occurrence of given prefix sum
prefixSum_map = defaultdict(int)
# prefix summation 0 is reached by selecting nothing
prefixSum_map[0] = 1
for number in nums:
# update prefix sum from first element to current position
cur_prefix_sum += number
# if curPrefixSum - k exist in map, then sub array with sum = k must exist in somewhere
if (cur_prefix_sum - k) in prefixSum_map:
counter += prefixSum_map[cur_prefix_sum - k]
# update occurrence of curPrefixSum
prefixSum_map[cur_prefix_sum] += 1
return counter
複雜度分析 用 前綴和 高速計算 區間和(以前正好學過)
令n=陣列總長度
時間複雜度:
從左到右線性掃描,逐步更新prefix sum,並且寫入到字典裡面,並且動態更新子陣列=k的出現次數,所需時間為O(n)。
空間複雜度:
成本耗費在字典prefixSum_map,最多儲存n種不同的前綴和,所耗空間最大為O(n)。
關鍵知識點
建造一個迴圈,從左到右,逐漸更新前綴和 prefix sum,接著檢查
prefix sum - k 這個比較小的值以前有沒有出現過?
假如有,代表已經找到子陣列=k的區間,累加子陣列=k的的出現次數。
也可以順便複習 Range Sum這題,加強鞏固關於使用 前綴和 高速計算區間和的技巧。
Reference:
